Making a galaxy map, Part 5: Overlays

Galaxy map with three mesh sets: very ionizing, some ionizing, and no ionizing with 50 or more stars.
Over the last few blog posts I've outlined the process I used to create a hot star map of the galaxy within 3000 pc. Along the way I mentioned many different choices I made for the map, from star filtering, to density calculations, to mesh selections.
How can we tell that these choices were appropriate and actually created the map I desired?
Answering this question is made more difficult by the revolutionary nature of the Gaia DR2 data set. There has never been a data set large enough and accurate enough to make a map of the galaxy beyond about 300 parsecs before. Gaia DR2 allows a map with a radius that is an order of magnitude larger. There are no other maps for comparison.
There is, fortunately, a very relevant and highly studied set of stars that we can use as a check on the map: the list of known ionizing stars, which is included as an overlay on the map. These extremely hot stars, either Wolf-Rayet stars or stars of class O-B3, emit intense ultraviolet radiation, ionizing any nearby hydrogen clouds by ripping electrons apart from protons, and producing red glowing HII regions visible for thousand of parsecs.
These ionizing stars, and the HII regions they create, are an obvious spiral arm marker in other galaxies, and creating lists of these stars in the Milky Way has been an important project for astronomers interested in mapping our home galaxy.
Roberta Humphreys first published a large list of highly luminous stars, including many ionizing stars, in her highly cited 1978 paper, Studies of luminous stars in nearby galaxies. I. Supergiants and O stars in the Milky Way [ADS link: 1978ApJS...38..309H] It was subsequently expanded by Douglas McElroy and Cindy Blaha and released in 1984. The catalog and a SIMBAD cross match is available from my blog post here.
More recently, researchers have created extensive catalogs of O stars and Wolf-Rayet stars.
Astronomers have also published lists of ionizing stars for individual HII regions. I have compiled these results into a list of more than 700 stars as described in this blog post.
Wright et. al., "The massive star population of Cygnus OB2", Mon. Not. R. Astron. Soc. 449, 741 (2015) have a list of ionizing stars in Vizier.
Finally, almost all of the 340 thousand stars I used to create the map have 2MASS cross matches. About half of these 2MASS identifiers have entries in the SIMBAD astronomical database. I downloaded the basic data for these stars and selected the stars with ionizing spectral types.
After combining all these lists and cross matching with the Gaia DR2 catalog using the 2MASS, Tycho-2 and UCAC4 cross match lists, I ended up with a list of more than 6000 ionizing stars. (I'll include this list in my resource post next week.)
I used the distance estimates from C.A.L. Bailer-Jones et. al. in "Estimating distances from parallaxes IV: Distances to 1.33 billion stars in Gaia Data Release 2" to place the stars on the map. About 5000 of the stars were within 3000 parsecs.
Here are the stars below:
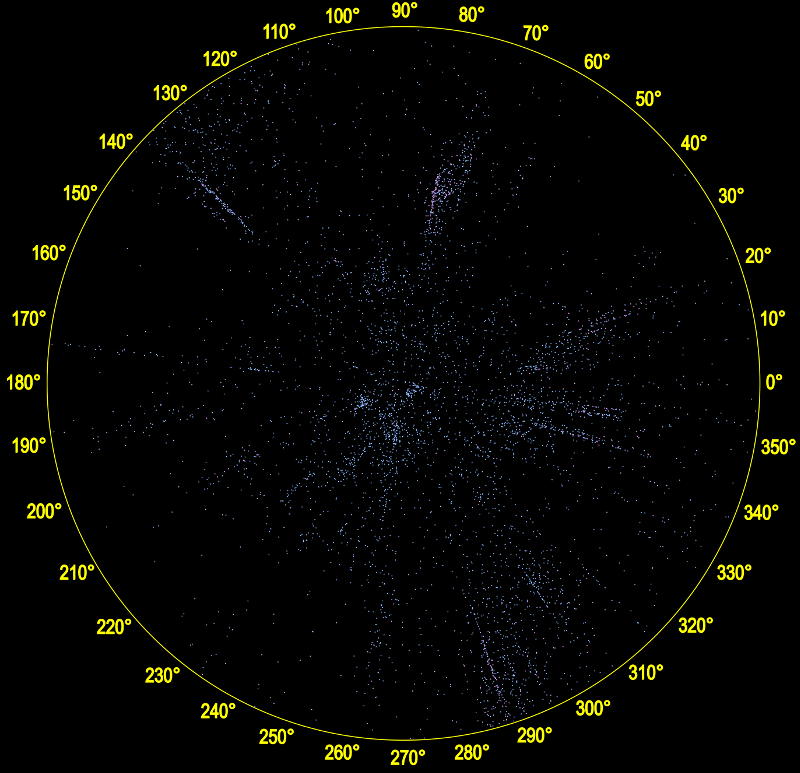
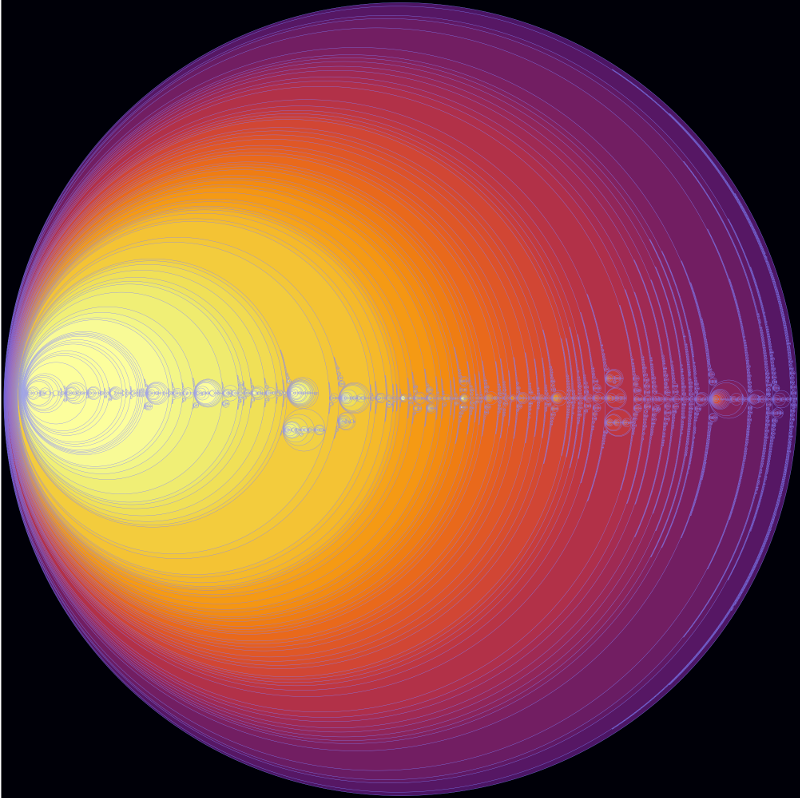
and here is the map with just the very ionizing mesh set:
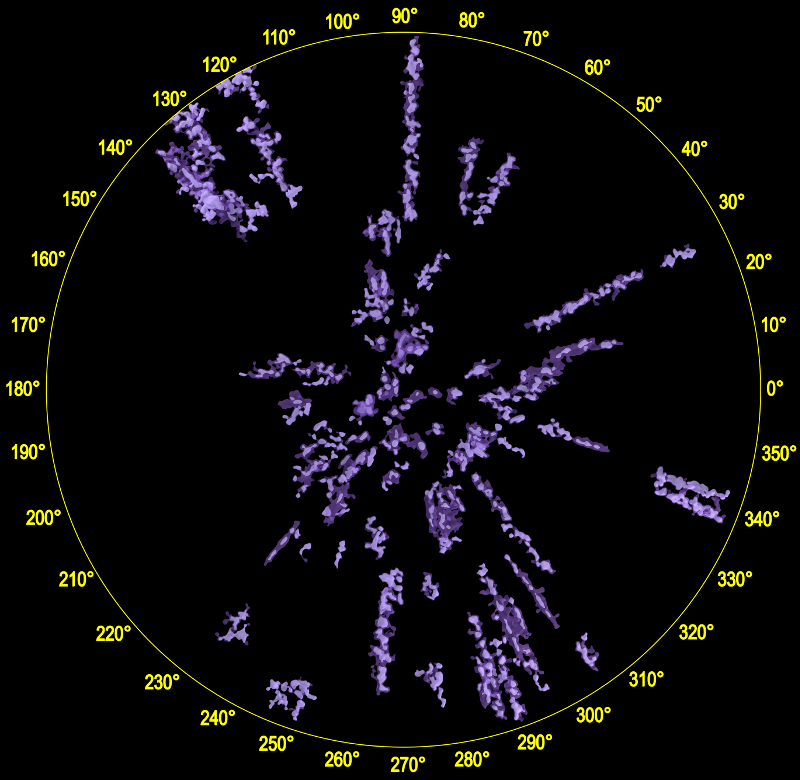
You can do a more detailed comparison by toggling on and off the ionizing stars on the interactive map site.
I conclude from this comparison that the map includes almost all the regions with known ionizing stars (the main exception in the above image being the highly reddened Cyg OB2 region, which shows up only in the cooler meshes). However the "very ionizing meshes" (which are selected using Gaia DR2 colours) also include a few regions that have few ionizing stars in my list. In a future blog post, I'll look more carefully at these "extra" regions. It will be interesting to see what happens to the map with Gaia DR3, currently expected in late 2020, which should have more accurate photometry.
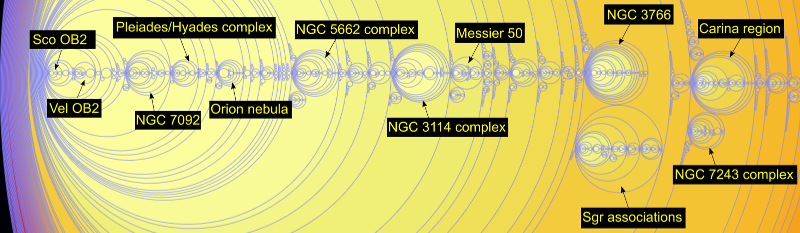
It is also interesting to compare my map with the recently released preprint on star clusters in Gaia DR2:
Cantat-Gaudin, T. et. al., "A Gaia DR2 view of the Open Cluster population in the Milky Way". Unfortunately the electronic data mentioned in that paper does not seem to have been released yet (or at least I cannot find it) so I'll have to resort to some ugly image scraping from the paper. I'll replace this with a proper map when I can get the data:
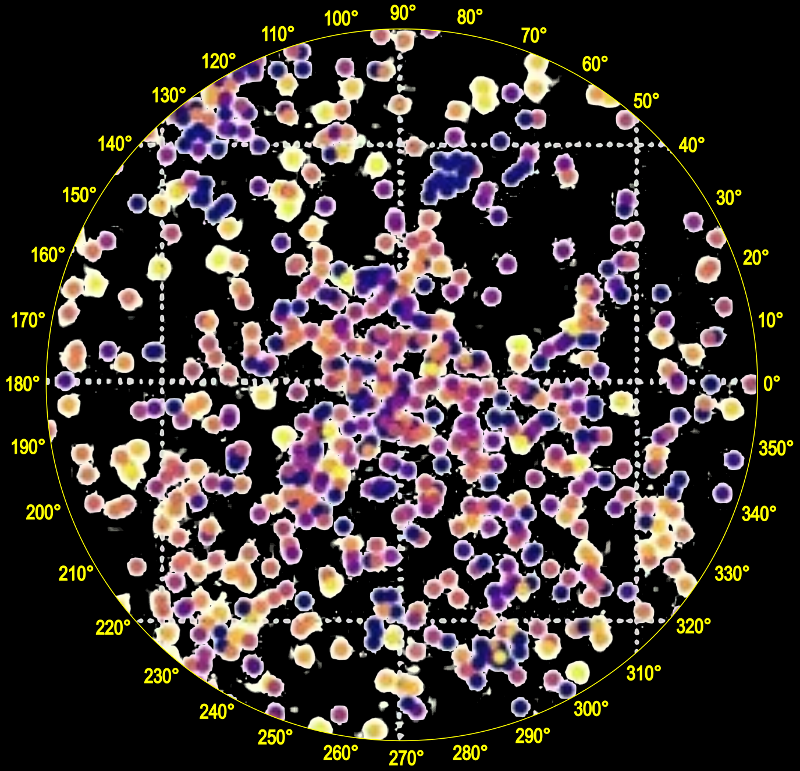
The blue and purple clusters are the youngest clusters. The yellow clusters are cooler clusters more than a billion years old so are not relevant for my hot star map.
All of these maps are consistent with three basic patterns for the ionizing stars within 3000 parsecs:
- The ionizing stars in the Perseus arm are concentrated in the Cassiopeia region between 115-140°. The ionizing stars in the third quadrant (180-270°) are not very concentrated except perhaps in the Vela molecular ridge.
- The Sagittarius arm is visible in the fourth quadrant (270-360°), especially in the Carina region and to a weaker extent in the first quadrant (0-90°)
- The Orion spur is visible as an extended diagonal slash between the Perseus and Sagittarius arms.
The full face-on map here also includes two additional features derived from subsets of the ionizing star list: HII regions are positioned on the map as described in this blog post and OB association labels are determined from the median distance to the star members as given in the 1984 Humphreys catalog, with the exception of the Cyg OB7 label, which I moved closer to the position of the Sh 2-117 HII region. The Cyg OB7 stars as listed in the Humphreys catalog were very widely distributed in Gaia DR2, leaving no clear position, but Cyg OB7 is often associated with this HII region, which includes the Pelican and North America nebulae.
There were also a small number of OB association labels from the Humphreys list that were positioned near no obvious star concentration or isosurface region (such as R 103 and R 105) and I removed those from the map. You can see these in the pdf linked from this blog post.
Finally, the full map includes dust concentrations within 2000 parsecs using the data cube provided at the download link on this page:
which is described in this preprint:
"3D maps of interstellar dust in the Local Arm: using Gaia, 2MASS and APOGEE-DR14" by Lallement et al.
Next week, in the last blog post in this series, I'll provide links to star lists, meshes, source code and other resources for the galaxy map.