All materials released under the Creative Commons By Attribution 4.0 license.
Credit: Kevin Jardine (Twitter: @galaxy_map)
Overview
How do you map 1.7 billion stars?
Here's a recent presentation that tries to answer this question. More detailed references can be found below:
The revolutionary Gaia DR2 release on 25 April 2018 contained an amazing amount of information that is a challenge to visualize.
Simply displaying the stars would be worse than an image of a Sahara sandstorm. Fortunately, there is another alternative.
The game plan
A technique called density isosurfaces is more commonly used to generate images from medical MRI scans.
In this technique we generate 3D surfaces consisting of a common density value, much like we can use contour lines on topographic maps to show regions of common elevation. In MRI scans this is human tissue density. For galaxy mapping we can use star density, counting the number of stars per cubic parsec. We can, in a way, use Gaia data to do an MRI scan of the Milky Way.
There is a crucial point about stars that affects mapping using this density technique.
This is that older cooler stars cannot be seen from a great distance, and tend to move around randomly from their place of birth. A random starscape does not give anything interesting to map.
So if you are going to make a large map, it often works better to focus on younger, hotter stars. These are usually closer to their birth places and can be seen for a long distance. And if you are going to make a smaller map, you can include cooler stars as well, but best to focus on large dense clumps as these will be closer to their birth places than a less dense random haze.
There is one major barrier to implementing this plan for larger maps, and that is dust. Dust can obscure and redden young hot stars and make them appear to be older cooler stars instead.
There was an attempt to provide information about reddening in the Gaia DR2 release, but it is not accurate enough for mapping. This is likely to be improved in future Gaia releases.
For this reason, astronomers have prepared special dereddened hot star subsets of the Gaia data set by adding additional information from other surveys. It turns out that infrared data is especially valuable in determining a star's true nature because infrared radiation is less affected by dust.
The hot star data sources
The Galaxy Map hot star density maps are derived from three star databases. The first is a set of about 600 thousand Gaia stars that have been dereddened using the 2MASS infrared survey. This data set is described in this paper:
Poggio, E., R. Drimmel, M. G. Lattanzi, R. L. Smart, A. Spagna, R. Andrae, C. A. L. Bailer-Jones et al. "The Galactic warp revealed by Gaia DR2 kinematics" Monthly Notices of the Royal Astronomical Society: Letters 481, no. 1 (2018): L21-L25.
(Thank you to Eloisa Poggio for providing the latest version of this data set on 30 August 2019.)
This was merged with a second StarHorse data set with an additional 200 thousand hot stars with (BPRP0 < -0.1) and (SH_GAIAFLAG == '000') and (SH_OUTFLAG == '00000') from:
Anders, Friedrich, et al. "Photo-astrometric distances, extinctions, and astrophysical parameters for Gaia DR2 stars brighter than G= 18." Astronomy & Astrophysics 628 (2019): A94.
Both these hot star data sets are missing stars close to the Sun. So they are supplemented with a database of about 10 thousand OB stars within 1 kpc using SIMBAD colours and Bailer-Jones distances derived from Gaia DR2.
Other star data sources
Star clumps with no temperature or colour limits are computed using Bailer-Jones distances for older maps. Recent maps use a zero point correction of -0.029 and the formula: distance in parallax = 1000/(plx-zero_point_correction) .
OB associations
OB association positions were computed from the median distance to the member stars given in the data set first described in:
Humphreys, R. M. "Studies of luminous stars in nearby galaxies. I. Supergiants and O stars in the Milky Way" Astrophysical Journal, Suppl. Ser., Vol. 38, p. 309 - 350.
HII regions
HII region positions were computed from the distance to known ionizing open clusters or using the median distance to known ionizing stars.
Star clusters
The newest maps use the Gaia DR2 open cluster catalog described in:
Cantat-Gaudin, T., et al. "Painting a portrait of the Galactic disc with its stellar clusters." arXiv preprint arXiv:2004.07274 (2020).
We calculate the cluster distances using the cluster parallax and a zero point correction of -0.029. distance in parallax = 1000/(plx-zero_point_correction)
We use this calculation rather than the distances provided in the 2020 open cluster catalog because it ensures that the clusters align with the Gaia density clumps.
For older maps:
The main data set for the star clusters was kindly provided by Tristan Cantat-Gaudin on 10 December 2019 and is described in this paper:
Cantat-Gaudin, T., and F. Anders. "Clusters and mirages: cataloguing stellar aggregates in the Milky Way." Astronomy & Astrophysics 633 (2020): A99.
This was supplemented by the new cluster data set described in:
Liu, Lei, and Xiaoying Pang. "A catalog of newly identified star clusters in GAIA DR2." The Astrophysical Journal Supplement Series 245.2 (2019): 32.
I removed some Liu Pang clusters that clearly duplicated Cantat-Gaudin clusters.
And also supplemented by the new clusters contained in this paper:
Castro-Ginard, A., et al. "Hunting for open clusters in Gaia DR2: 582 new open clusters in the Galactic disc." Astronomy & Astrophysics 635 (2020): A45.
Dust
Rosine Lallement has led a team that has published several important papers on dust distribution derived from the Gaia data. The most recent dust data set is used on our maps and is described in:
Lallement, R., et al. "Gaia-2MASS 3D maps of Galactic interstellar dust within 3 kpc." Astronomy & Astrophysics 625 (2019): A135.
Molecular Clouds
Many of the dust cloud labels are derived from the molecular cloud maps contained in:
Zucker, Catherine, et al. "A compendium of distances to molecular clouds in the Star Formation Handbook." Astronomy & Astrophysics 633 (2020): A51.
Luminous stars
Several of the maps contain overlays of luminous stars. These are determined by taking Gaia DR2 stars with low astrometry errors (err/plx< 0.2, G > 5 and RUWE < 1.4). If these stars are in the 2MASS and StarHorse catalogs and the StarHorse quality flags are (SH_GAIAFLAG == '000') and (SH_OUTFLAG == '00000') and the 2MASS quality flag is 'AAA', then we use the StarHorse dereddened absolute magnitude, otherwise we calculate the absolute magnitude using Gaia G and the parallax with a zero point correction of -0.029. We've also supplemented this data set with Hipparcos 2007 re-analysis stars with err/plx < 0.2 if they are not in our list.
We filter out Gaia stars with G < 5 because Gaia stars with very high relative magnitude are known to have unreliable parallaxes, as described in this research note:
Funding for the DPAC has been provided by national institutions, in particular the institutions participating in the Gaia Multilateral Agreement.
This research has made use of the SIMBAD database, operated at CDS, Strasbourg, France.
Many members of the Gaia team have provided useful advice and aid but in particular I would like to thank Anthony Brown for strongly encouraging this project and Ronald Drimmel for providing invaluable data and technical advice. I would also like to thank Stefan Payne-Wardenaar for help with Blender materials.
The galactic bar is located in the inner galaxy at a large distance from the Sun. Its closest approach lies in the heavily dust obscured first quadrant. Nevertheless, can we detect the bar using the Gaia DR2 data set? I think that the answer is yes if we are willing to map it using quantitative star counts and do not expect a great deal of detail.
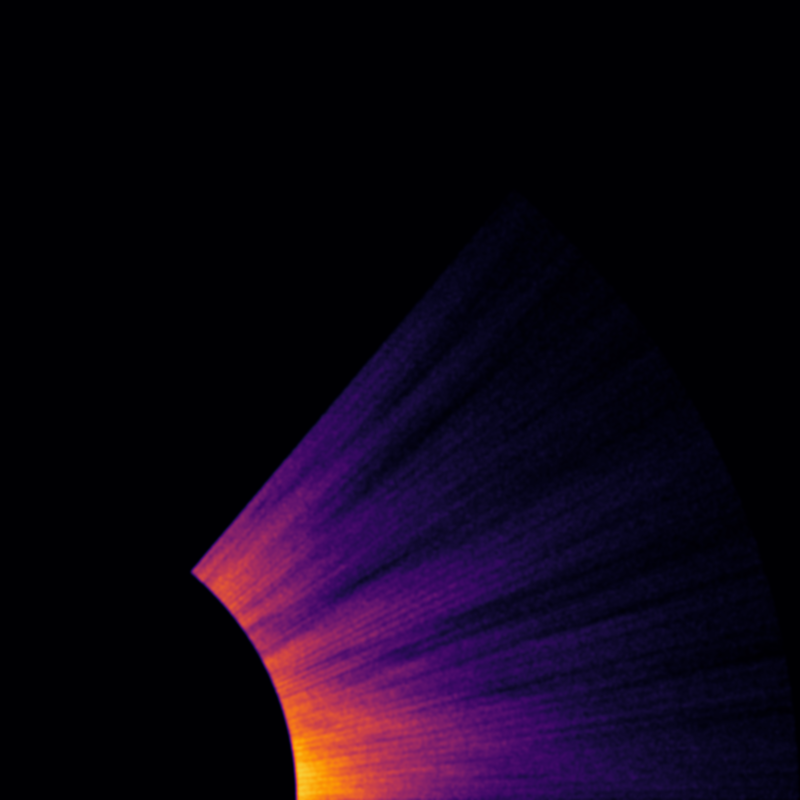
Here's the region in the first quadrant that we want to map:
What helps is that the bar extends far above and below the galactic plane and ends in a point. That creates a geometry that can be detected despite all the data limitations.
If we just try to map the bar in the galactic plane, we do not get an encouraging result because of all the dust extinction:
This is a density map of stars between 0 and 50 degrees in galactic longitude and between 3 and 8 kpc. (The parallax errors are so high at this distance that I did not impose any error constraints on the stars except RUWE < 1.4)
However, if we look 400 parsecs below the galactic plane, we can avoid the extinction but now the parallax errors are so high that much of the detail is blurred out:
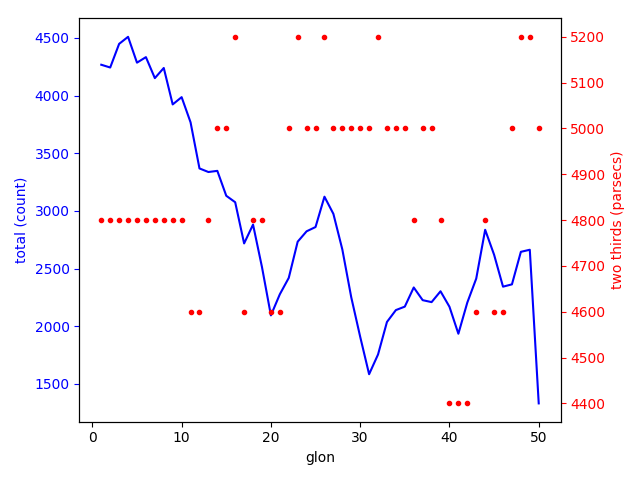
What I think helps is a more quantitative approach using star counts. Here's a graph that analyzes the star counts and distribution, also for a slice taken 400 parsecs below the galactic plane:
The x axis shows the galactic longitude. The blue data and left y axis shows the total Gaia star count between 3 and 8 kpc for that degree longitude at 400 parsecs below the graphics plane. The red dots and right y axis shows how far you need to go in distance beyond 3 kpc to find two-thirds of the stars for that degree longitude.
What you find is that we start with about 4500 stars close to zero degrees longitude and that as we approach 20 degrees the star count drops and so does the distance required to find two-thirds of the stars. What this says to me is that from 0 to 20 degrees the stars are in a structure that starts wide and gradually narrows to a point - just what you would expect from a bar shaped structure.
I've tried numerous slices and I see the same pattern with the point (end of the bar) occurring around 20 degrees from 400 parsecs below the galactic plane and beyond, as well as about 25-30 degrees from 400 parsecs above the galactic plane and beyond. Larger than about 20-25 degrees we see a pattern that is not so clear but arguably could be two spiral arms passing at different distances from the end of the bar below the galactic plane and one spiral arm above the galactic plane (the arm that passes closest to the end of the bar runs entirely below the galactic plane).
So in short, in the region close to the bar, we seem to see a spiral arm (the Centaurus arm) intersect the bar close to and beneath the tip.
Within 400 parsecs of the galactic plane, the pattern becomes more chaotic, probably because of dust extinction.
The new version of the galaxy map, (http://galaxymap.org/dr2) released today, supports searching for stars. You can enter any Gaia DR2 source identifier or Simbad identifier in the search box at the upper right and if the object has a parallax, its position will be shown on the map. The most probable location will be shown with a green cross hair and other possible locations are shown along a light blue line. If Simbad has more information on the object, some of it will be shown in a pop up box, including common names, coordinates, z height, spectrum and absolute magnitude.
Because Simbad includes all the Hipparcos parallaxes, it is possible to search for Hipparcos stars even if they are too bright to appear in Gaia DR2. Simbad identifiers include common names so, for example, you can search for "Betelgeuse".
By default, the Bailer-Jones et.al. distance catalog is used to determine Gaia DR2 distances. You can turn off Bailer-Jones distances to use the simple reciprocal calculation instead (only available when err/plx < 0.2) by unticking the Bailer-Jones distances box..
Currently the Bailer-Jones catalog is only available through the Heidelberg ARI TAP service which does not include the CORS headers that allow queries to be accessed via JavaScript applications. To solve this I am using a sneaky trick involving a NodeJS proxy running on my own server that accesses the Heidelberg service. I hope that remains stable until the Bailer-Jones catalog is available via Vizier (or the TAP service adds the appropriate headers to support client applications).
In addition to search, I've added a display of longitude and galactic plane distance at the bottom left corner that tracks your mouse pointer (not available for mobile devices).
These are for use outside of Gaia Sky and are larger more detailed versions. As the hot star, dust and HII region meshes were created using different bin sizes and orientations, it probably makes sense to convert them to a standard coordinate system representing parsecs where the galactic centre (0 degrees) is to the right and the sun is at (0,0,0).
Here are the transformations:
hot star meshes: multiply mesh coordinates by 3, translate by (-3027,-2997,-597), rotate by -90 degrees
dust meshes: multiply mesh coordinates by 5, translate by (-2045,-1995,-300), rotate by -90 degrees
HII regions: no transformation should be necessary.