Panurania
In my last blog post, I showed 3D slices of a TGAS density function that reveal the concentrations of high temperature stars. There is a very clever algorithm called the marching cubes algorithm that can take such 3D slices and convert them into 3D surface meshes that can be rendered in a 3D graphics program. In my case I used the vtkSliceCubes function in a Python port of the amazing VTK graphics library to generate the meshes and then rendered the resulting meshes in the Blender 3D program.
I'll be presenting some of these Blender images over the next few blog posts.
It is important to keep in mind that TGAS is missing many stars (especially high temperature stars) in the solar neighbourhood and the maps we generate using it will inevitably be incomplete. We can look forward to more complete maps a year from now with the release of Gaia DR2.
The marching cubes algorithm takes a function f on 3D points and a number v and generates isosurfaces that consist of all points (x,y,z) where f(z,y,z) >= v.
The isosurface typically consists of a number of disconnected pieces.
The value v ranges between a minimum value (usually 0) and a maximum value. At the minimum value, there is always one isosurface piece that contains all the points.
As the value v increases, the isosurface typically fragments into more and smaller pieces, until v reaches its maximum value when the isosurface may be empty or consists of a few small pieces around points that take on the maximum value.
The TGAS isosurfaces follow a similar pattern with the density function that I described in my previous blog posts, but what is interesting is what happens to the isosurface when v ranges between its maximum and minimum value.
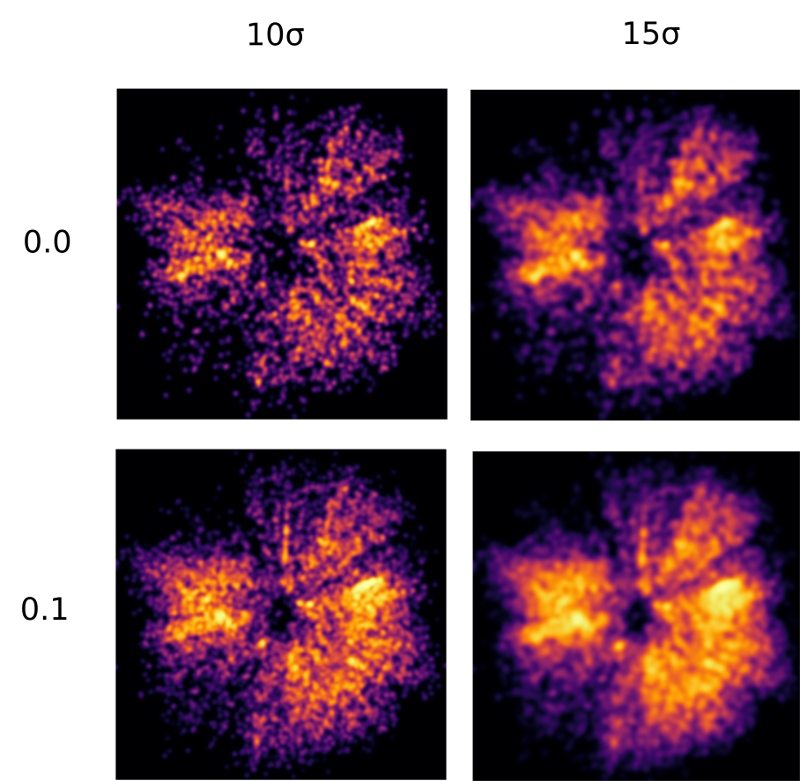
Here is a table showing information about the isosurfaces as the TGAS temperature density v ranges between 5% and 95% of its maximum value.
| density | stars | star percentage | regions with 90% stars | stars in 90% regions |
|---|---|---|---|---|
| 5% | 19305 | 95.27% | 1 | 18778 |
| 10% | 18241 | 90.02% | 1 | 17655 |
| 15% | 16182 | 79.86% | 1 | 15811 |
| 20% | 14480 | 71.46% | 1 | 14071 |
| 25% | 12712 | 62.74% | 1 | 12249 |
| 30% | 10945 | 54.01% | 1 | 10485 |
| 35% | 9264 | 45.72% | 1 | 8769 |
| 40% | 7819 | 38.59% | 3 | 7308 |
| 45% | 6527 | 32.21% | 3 | 6054 |
| 50% | 5292 | 26.12% | 3 | 4834 |
| 55% | 4183 | 20.64% | 3 | 3854 |
| 60% | 3239 | 15.98% | 5 | 2934 |
| 65% | 2448 | 12.08% | 8 | 2225 |
| 70% | 1747 | 8.62% | 14 | 1574 |
| 75% | 1222 | 6.03% | 15 | 1100 |
| 80% | 807 | 3.98% | 10 | 727 |
| 85% | 486 | 2.40% | 9 | 439 |
| 90% | 214 | 1.06% | 9 | 195 |
| 95% | 62 | 0.31% | 4 | 60 |
The first column is the density value used to generate the isosurfaces. The second column is the number of high temperature stars inside the isosurface. The third column is the percentage of high temperature stars that are inside the isosurface compared to all TGAS high temperature stars. There are 20263 hot stars (color index <= 0) in TGAS with error ratios less than 0.2. So, for example, 95.27% of these 20623 stars are inside the isosurface where the density is greater than or equal to 5%.
The fourth column is the number of isosurface pieces that contain 90% of the isosurface stars.
It is not surprising that almost all the stars are within the 5% isosurface. What is more interesting is what happens as the density value goes up. Even when we reach 35% density, 45.72% of all the hot TGAS stars are still within the isosurface, and more than 90% of these are still within one giant stellar "supercontinent".
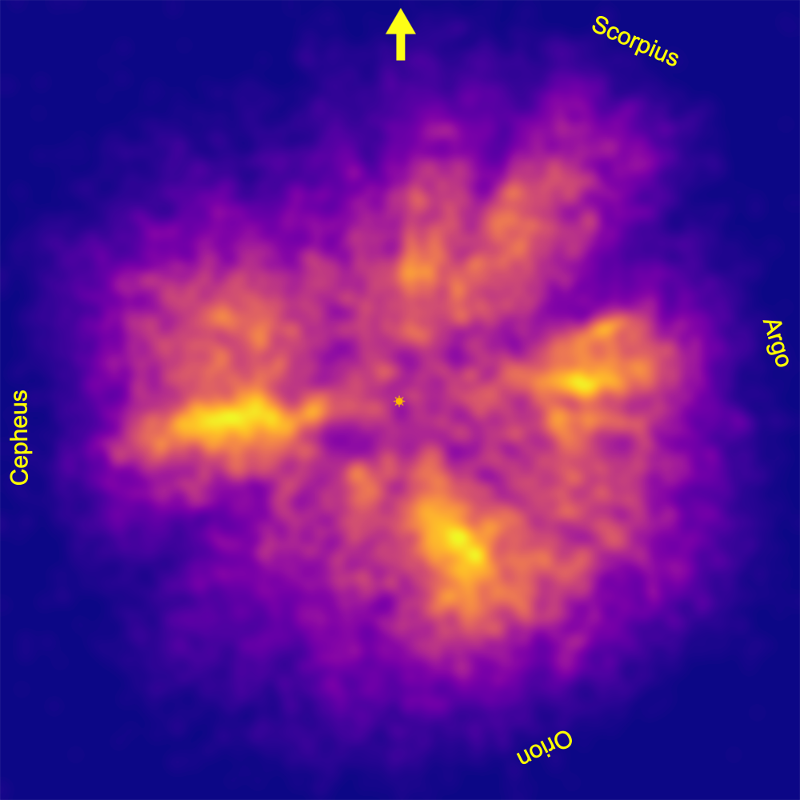
After 35%, the supercontinent breaks into three smaller stellar continents. The three continents are also persistent and only start to break up at 60% density, when the isosurfaces start to fragment into regions of dense hot star concentrations including well known local OB associations such as Ori OB1 and Sco OB2.
Since the stellar supercontinent and three denser continents contained within it are so persistent, this suggests that they are real structures and not just artifacts of the density function.
Earth once had a supercontinent that contained most of its land, called Pangaea. It seems inevitable therefore to call the stellar supercontinent Panurania, after both the goddess Gaea's husband Ouranos/Uranus, the god of the sky, and his great granddaughter Urania, the muse of astronomy.
We'll look at Panurania in more detail in the next blog post, but here is a teaser image of the 25% density isosurface rendered in Blender.
You can see that it has a very distinctive shape. We'll look at some possible reasons in the next blog post.